1.引言
对于网站经营者来说,让用户等待的时间过长,也许会造成毁灭性的后果。
我见过很多人为了享用某家特色小吃而在餐厅门口乐此不疲地排着长队,但没有听说有多少用户执着地等待着一个速度缓慢的站点而不去尝试别的站点。——《构建高性能web站点》
2.了解性能差异
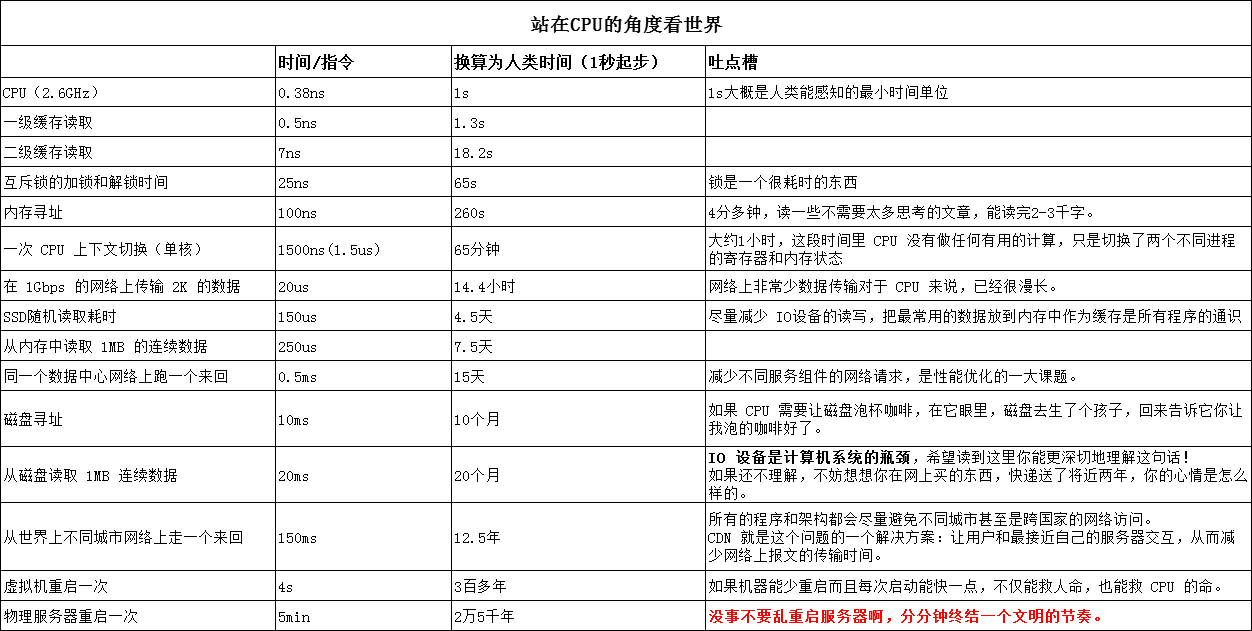
了解性能差异:站在CPU的角度看世界
内容来源:http://cizixs.com/2017/01/03/how-slow-is-disk-and-network/
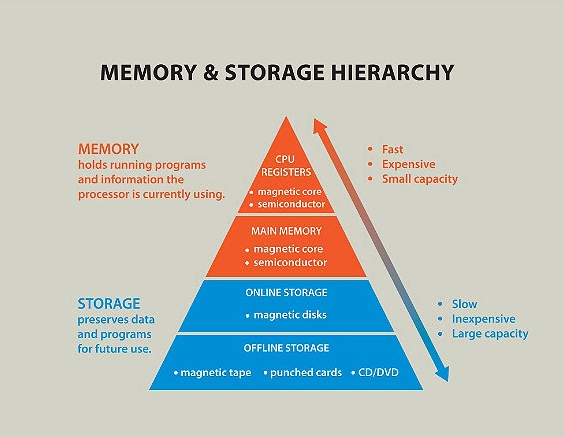
计算机不同组件速度差异金字塔见下图(不够直观)
越往上速度越快,容量越小,而价格越高。
我们都知道CPU很快,硬盘很慢,那么站在CPU的角度,这些设备到底有多慢呢?见下方图表
扩展阅读:
世界各地ping文时间:https://wondernetwork.com/pings/
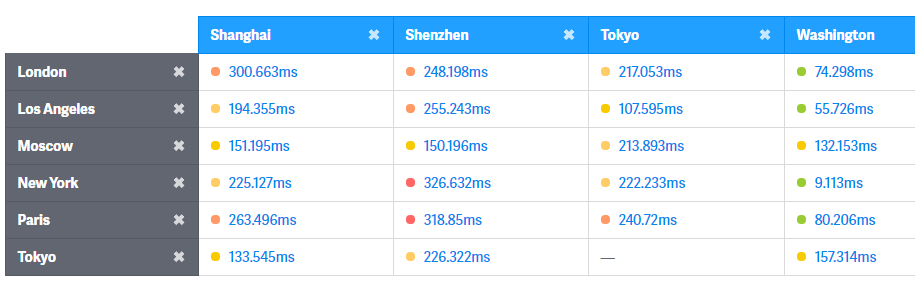
结论:磁盘和网络真的很慢,性能优化是个复杂的系统性的活。
3.记一次性能优化的过程
来自某接口需求,性能要求支撑万级TPS,10ms返回。
程序逻辑很简单,只是简单的k/v请求。
技术选型:
选用openresty容器(一个基于 Nginx 与Lua 的高性能 Web 平台),redis存储(毫无悬念),避免磁盘读取拖慢速度
服务器配置:
部署在同一区域(毫无悬念),减少不同城市网络访问。
8核,16G
服务稳定性要求:
线上服务没有返回时,将进入离线计算,调用端做了保护,因此就算服务崩了也没事,唯一关注:快!
因此大胆的作吧~
服务器内核参数调整:
ulimit -n 999999
重启失效
或:
在/etc/security/limits.conf加入一下内容
# 最大不能超过fs.nr_open值, 分别为单用户进程最大文件打开数,soft指软性限制,hard指硬性限制
# End of file
root soft nofile 999999
root hard nofile 999999
* soft nofile 999999
* hard nofile 999999
重启使上述内容生效
不愿意重启就使用以下命令
sysctl -p
然,并没有什么卵用。。。
wrk压力测试结果:上万并发,50%响应100多ms,90%响应200多ms,差了一个数量级
继续优化,还有什么需要考虑?
第一步,考虑优化web容器。
nginx参数优化
vim nginx.conf
nginx配置:
# 子进程允许打开的连接数(nginx.conf)及 IO 选择
#改为系统核数
# nginx 进程数,按照 CPU 数目指定
worker_processes 8;
# nginx 子进程允许打开的文件次数
worker_rlimit_nofile 102400;
events {
# 子进程连接数
worker_connections 65535;
use epoll; #epoll是多路复用IO(I/O Multiplexing)中的一种方式,但是仅用于linux2.6以上内核,可以大大提高nginx的性能
}
如果你使用Linux 2.6+,你应该使用epoll。如果你使用*BSD,你应该使用kqueue。
Web服务器所做的工作的本质就是,争取以最快的速度将内核缓冲区中的用户请求数据一个不剩地都拿回来,然后尽最大努力同时快速处理完这些请求,并将响应数据放到内核维护的另一块用于发送数据的缓冲区中,接下来再尽快处理下一拨请求,并尽量让用户请求在内核缓冲区中不要等太久。——《构建高性能web站点》
IO如此之慢,阻塞IO不可取,因此只能考虑非阻塞IO方式。
epoll,select,poll的区别:https://www.cnblogs.com/jeakeven/p/5435916.html

第二步:linux内核tcp调优
/etc/sysctl.conf是一个允许你改变正在运行中的Linux系统的接口。
它包含一些TCP/IP堆栈和虚拟内存系统的高级选项,可用来控制Linux网络配置
vim /etc/sysctl.conf
net.ipv4.tcp_tw_reuse = 1 #表示是否允许将处于TIME-WAIT状态的socket(TIME-WAIT的端口)用于新的TCP连接 。
net.ipv4.tcp_tw_recycle = 1 #能够更快地回收TIME-WAIT套接字。其他场景要小心调整此参数,可能引起连接错误。
net.ipv4.ip_local_port_range = 10000 65000 #端口范围
附上开发环境配置前后压测对比(至少10倍提升!):
优化背后的原理:
TCP三次握手,四次挥手
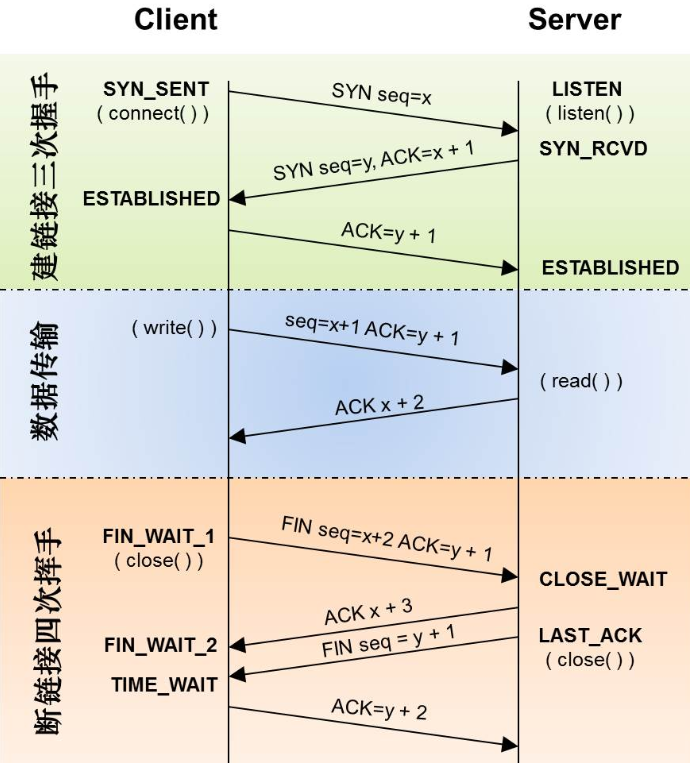
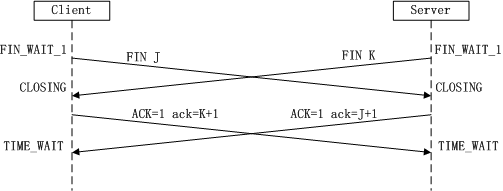
什么是TCP TIME-WAIT状态
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭
被动关闭:
扩展,其他优化,可自行了解
| 参数名 | 默认值 | 调优值 | 说明 |
|---|---|---|---|
| fs.file-max | 4096 | 999999 | 表示系统级别的能够打开的文件句柄的数量。是对整个系统的限制,并不是针对用户的。 |
| net.ipv4.tcp_rmem | 4096 87380 4011232 | 4096 4096 16777216 | 为自动调优定义socket使用的内存。包含3个整数值,分别是:min,default,max第一个值是为socket接收缓冲区分配的最少字节数;第二个值是默认值(该值会被rmem_default覆盖),缓冲区在系统负载不重的情况下可以增长到这个值;第三个值是接收缓冲区空间的最大字节数(该值会被rmem_max覆盖)。 |
| net.ipv4.tcp_wmem | 4096 16384 4011232 | 4096 4096 16777216 | 为自动调优定义socket使用的内存。包含3个整数值,分别是:min,default,max第一个值是为socket发送缓冲区分配的最少字节数;第二个值是默认值(该值会被wmem_default覆盖),缓冲区在系统负载不重的情况下可以增长到这个值;第三个值是发送缓冲区空间的最大字节数(该值会被wmem_max覆盖)。 |
| net.ipv4.tcp_mem | 94011 125351 188022 | 786432 2097152 3145728 | 确定TCP栈应该如何反映内存使用,每个值的单位都是内存页(通常是4KB)。包含3个整数值,分别是:low,pressure,high第一个值是内存使用的下限;第二个值是内存压力模式开始对缓冲区使用应用压力的上限;第三个值是内存使用的上限。在这个层次上可以将报文丢弃,从而减少对内存的使用。对于较大的BDP可以增大这些值(注意,其单位是内存页而不是字节)。 |
| net.ipv4.tcp_keepalive_time | 7200 | 15 | TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效。默认7200s(2 hours)和如下参数一起使用。tcp_keepalive_probes = 9tcp_keepalive_intvl = 75 seconds意思是如果某个TCP连接在idle tcp_keepalive_time后,内核才发起probe.如果probe tcp_keepalive_probes次(每次tcp_keepalive_intvl秒)不成功,内核才彻底放弃,认为该连接已失效 |
| net.ipv4.tcp_fin_timeout | 60 | 30 | 对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间(秒)。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。 |
| net.ipv4.tcp_max_tw_buckets | 180000 | 204800 | 设置保持TIME_WAIT的最大数量,如果超过这个数量,TIME_WAIT将立刻清楚并打印警告信息。默认18W,可调大 用来防范简单的DoS攻击,可以控制TIME_WAIT的最大数量建议使用默认值,不建议调小不恰当配置会出现Time wait bucket table overflow 报错# see details in https://help.aliyun.com/knowledge_detail/41334.html阿里云服务器默认配置5000 |
| net.ipv4.tcp_max_syn_backlog | 2048 | 16384 | 对于还未获得对方确认的连接请求,可保存在队列中的最大数目。如果服务器经常出现过载,可以尝试增加这个数字。 |
| net.ipv4.tcp_tw_reuse | 0 | 1 | 表示是否允许将处于TIME-WAIT状态的socket(TIME-WAIT的端口)用于新的TCP连接 。 |
| net.ipv4.tcp_tw_recycle | 0 | 1 | 能够更快地回收TIME-WAIT套接字。其他场景要小心调整此参数,可能引起连接错误。 |
| net.ipv4.tcp_fin_timeout | 60 | 15 | 对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间(秒)。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。 |
| net.ipv4.tcp_max_orphans | 8192 | 131072 | 系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量,那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制,纯粹为了抵御那些简单的 DoS 攻击,千万不要依赖这个或是人为的降低这个限制。对于net.ipv4.tcp_max_orphans = 65536,当orphans达到32768个时,会报Out of socket memory,此时占用内存 32K*64KB=2048MB=2GB |
| net.ipv4.tcp_syncookies | 0 | 1 | 0表示禁用,1表示启用,表示开启SYN Cookies,当SYN等待队列溢出时,启用cookies来处理,可以防范少量的SYN攻击,默认为0,表示关闭 |
| net.ipv4.ip_local_port_range | 32768 61000 | 10000 65000 | 端口范围 |
| net.core.netdev_max_backlog | 1000 | 8096 | 在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。 |
| net.core.somaxconn | 128 | 262144 | 定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数。用于调节系统同时发起的tcp连接数,在高并发请求中,默认的值可能会导致连接超时或重传,因此,需要结合并发请求数来调节此值。 |
| net.core.rmem_default | 110592 | 262144 | 默认的TCP数据接收窗口大小(字节)。 |
| net.core.wmem_default | 110592 | 262144 | 默认的TCP数据发送窗口大小(字节)。 |
| net.core.rmem_max | 131071 | 16777216 | 最大的TCP数据接收窗口(字节)。 |
| net.core.wmem_max | 131071 | 16777216 | 最大的TCP数据发送窗口(字节)。 |
net.ipv4.tcp_timestamps = 1 //在net.ipv4.tcp_tw_recycle设置为1的时候,这个选择最好加上
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 20480
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
wrk压力测试工具介绍:
wrk 的一个很好的特性就是能用很少的线程压出很大的并发量. 原因是它使用了一些操作系统特定的高性能 io 机制, 比如 select, epoll, kqueue 等. 安装很简单,见网上教程。此处不啰嗦。
[root@localhost ~]# dmesg
possible SYN flooding on port 80. Sending cookies.
TCP: time wait bucket table overflow
最后一次调整,使用工具strace进行跟踪:
日志中多次出现:
17:31:21.937510 socket(PF_INET, SOCK_STREAM|SOCK_CLOEXEC, IPPROTO_IP) = 18 <0.000015>
17:31:21.937550 ioctl(18, FIONBIO, [1]) = 0 <0.000006>
17:31:21.937576 fcntl(18, F_SETFD, FD_CLOEXEC) = 0 <0.000006>
17:31:21.937597 epoll_ctl(7, EPOLL_CTL_ADD, 18, {EPOLLIN|EPOLLOUT|EPOLLRDHUP|EPOLLET, {u32=2565218496, u64=140516715274432}}) = 0 <0.000007>
17:31:21.937621 connect(18, {sa_family=AF_INET, sin_port=htons(6379), sin_addr=inet_addr(“127.0.0.1”)}, 16) = -1 EINPROGRESS (Operation now in progress) <0.000025>
17:31:21.937669 recvfrom(16, “$49\r\n0109,010103,032202,0402,080”…, 4096, 0, NULL, NULL) = 56 <0.000008>
17:31:21.937709 close(16) = 0 <0.000018>
结论:多次和redis进行交互。
第四次优化点:
nginx中配置:
upstream redis_nodes {
server 127.0.0.1:6379;
keepalive 1024;
}
调整后,TPS从3K到9K,响应时间从300多ms降到20多ms.
使用工具strace进行跟踪,再也没有出现以上日志。
结论:
天下武功,唯快不破~
